Library Concepts
The following picture shows the main flow diagram behind all OpenTL-based applications.
This scheme follows our model-based tracking pipeline concept, which produces the desired output (state probability density estimation) starting from raw image data and going through multiple processing levels.
![]()
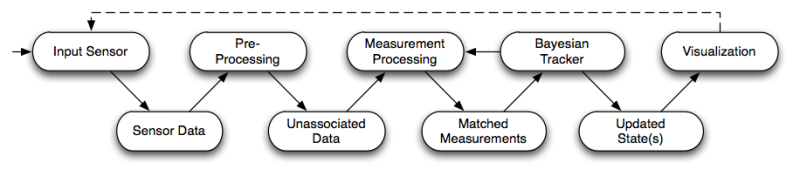 In our framework, any tracking pipeline consists of the following steps:
In our framework, any tracking pipeline consists of the following steps:
- Sensory input: raw image data are obtained at a given timestamp (the clock symbol above)
- Pre-processing: model- and state-free information processing is performed on the raw data, in order to produce information related to a given set of visual modalities (edge detection, color segmentation, etc.)
-
Measurement processing: the object model (shape and appearance), as well as its current state prediction
from the Bayesian tracker, are used in order to produce target-associated measurements.
These data can be defined at different levels (pixel maps, feature sets, or maximum-likelihood state estimates),
and will be delivered to the Bayesian tracker for state update.
Here, a static data fusion process can take place, that will combine multi-modal and multi-camera data into a single set of measurements. Alternatively, data fusion can be deferred to the Bayesian tracker, that will perform a dynamic fusion during the state update. - The Bayesian tracker performs, for each target, two main tasks: a state prediction using the dynamical object models and the current measurement timestamp, and a state update after the measurement processing. This general scheme holds for a large class of methods such as Gaussian filters (Kalman-based) and Monte-Carlo filters (particle-based).
- Post-processing and visualization of the updated state are the last stage of the pipeline. Here, a check for lost track and re-initialization can be performed.
Library Architecture
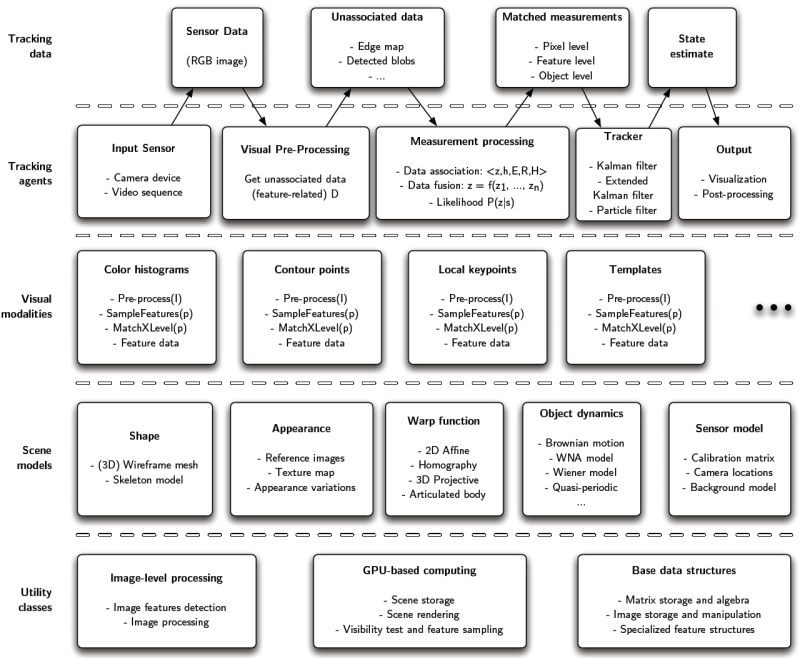
The picture below shows an abstract organization of functionalities inside OpenTL, where the layers reflect the semantics of each module involved:
- Utility classes are meant to provide the base data structures and image-level functionalities.
- Scene models consist of all available prior information: objects shape, appearance and motion, sensor devices, as well as useful context information (such as background models).
- Visual modalities provide the main information processing facilities (measurement and data association) for the pose estimation task. Although of a variable nature, in OpenTL they are all derived from a common abstraction.
- Tracking agents execute the respective part of the tracking pipeline, and exchange data in different forms, possibly using thread synchronization mechanisms and timestamps.
Library Modules
Following the previous abstraction, in this section we describe the internal module implementation of OpenTL, also organized in a hierarchical way that reflects dependencies across modules (indicated by arrows).
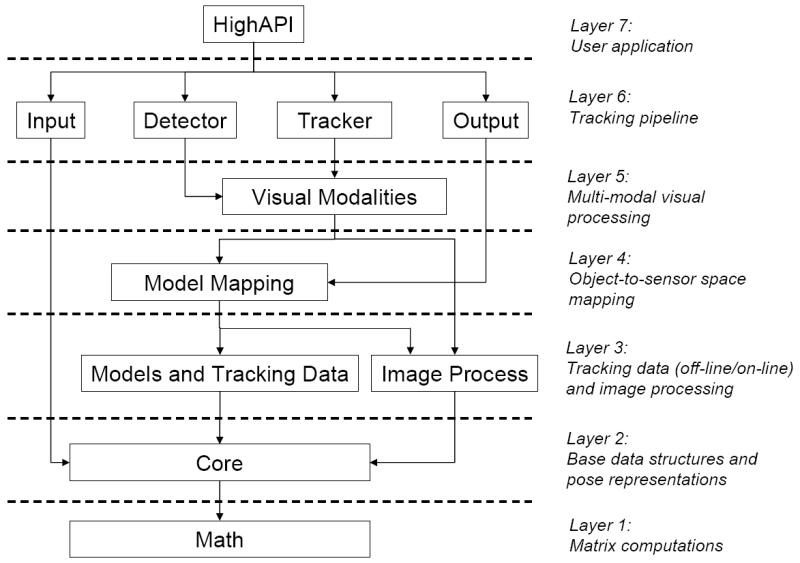
Layer 7: User Application
The HighAPI module in the topmost layer is finally meant to encapsulate the tracking pipeline in a more compact and user-friendly API, with an easier system and parameter specification. (currently work in progress)Layer 6: Tracking pipeline
Here the main tracking pipeline is realized, through the main abstractions tracker and detector, as well as sensory input and output visualization.- Input module: Common abstraction for input sensor devices (e.g. FireWire, USB and Ethernet cameras), providing open/init/close and data acquisition methods. It depends on opentl::core, because of the Image data type.
- Detector module: Common abstraction for object detection (model- based and model-free). Its purpose is to find new targets (=initial states) as well as remove lost tracks, without any prior information about number and location of the new targets, eventually using knowledge of the already existing targets.
- Tracker module: Here several Bayesian trackers, including Gaussian- based Filters (such as the Extended Kalman Filter) and Monte-Carlo Filters (particle or MCMC Filters) are implemented under the same abstraction - prediction, measurement, data association and fusion, correction. It depends on Modalities, because the measurement is performed by calling the Likelihood, which in turn calls the modality processing tree.
- Output module: Classes for output visualization (e.g. model rendering), post-processing (e.g. track loss detection) and simple control tasks (e.g. pan-tilt unit controller through a serial port). It depends on ModelProjection, because of the OpenGL rendering and mapping facilities.